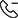中文
中文

在许多项目中,Raspberry Pi被用作监控摄像头或执行机器学习任务。在这些场景中,图像中经常包含应用程序感兴趣的文本信息。我们希望提取这些信息并将其转换,以便通过程序分析文本。Raspberry Pi也能实现这种文本识别,而且并不困难。我们可以从静态图像或摄像头的实时流中读取文本。
在本教程中,我们将探讨如何使用Raspberry Pi实现文本识别,以及为此需要哪些组件。
开始前的必要组件
该应用的主要部分是纯软件基础的。因此,我们只需要少量的硬件来设置文本识别。我们将需要并使用以下组件:
- 强大的Raspberry Pi(例如 Model 4)
- 官方Raspberry Pi摄像头,或者:USB 网络摄像头
- 电源连接:micro USB 线缆和 USB 适配器
可以使用屏幕、键盘和鼠标,但由于我们远程操作Raspberry Pi,因此它们并非必需。因此,您应该已经相应地设置了Raspberry Pi,并启用了 SSH,还建立了远程桌面连接。之后,我们就可以直接开始了。
使用 SSH 和 Putty 远程访问 Raspberry Pi:
https://tutorials-raspberrypi.com/raspberry-pi-remote-access-by-using-ssh-and-putty/
如何建立 Raspberry Pi 远程桌面连接:
https://tutorials-raspberrypi.com/raspberry-pi-remote-desktop-connection/
什么是文本识别(OCR)以及它在Raspberry Pi上是如何工作的?
简而言之,图像上的文本识别(光学字符识别或简称 OCR)实际上是识别单个字母。如果它们足够接近,就会形成一个单词。
https://en.wikipedia.org/wiki/Optical_character_recognition
在之前的教程中,我们已经看到可以训练一个模型来识别图像上的物体。如果我们现在训练所有(拉丁)字母——而不是物体——我们也可以通过模型再次识别它们。
理论上,这是可行的,但需要付出很多努力。必须先训练不同的字体、颜色、格式等。但是,我们想节省为此所需的时间。
因此,我们使用来自 Google 的 Tesseract 库。它已包含此类模型,并且经过了许多开发人员的优化。
Tesseract 库:https://github.com/tesseract-ocr/tesseract
安装 Tesseract OCR 库
我们可以自己编译 Tesseract,或者简单地通过包管理器安装它。后者可以通过以下命令轻松完成:
sudo apt install tesseract-ocr我们可以使用tesseract -v 轻松检查安装是否成功。
现在,我们可以进行第一次小测试。为此,我们将使用这张图片: 您可以通过以下方式下载它:
您可以通过以下方式下载它:
wget https://tutorials-raspberrypi.de/wp-content/uploads/coffee-ocr.jpg然后,我们执行以下命令:
tesseract coffee-ocr.jpg stdout输出如下所示:
Warning: Invalid resolution 0 dpi. Using 70 instead.
Estimating resolution as 554
COFFEE因此,在我们的输入图像中,文本“COFFEE”被识别出来了。
由于我们想在 Python 脚本中使用整个功能,因此我们需要一些库,如 OpenCV 和 Tesseract 的 Python 包装器。
OpenCV:https://opencv.org/
我们通过 Python 包管理器安装它们:
pip3 install opencv-python pillow pytesseract imutils numpy在Raspberry Pi上通过 Python 脚本测试文本识别
到目前为止,我们仅在未处理的彩色图像上尝试识别单词。预处理步骤通常可以改善结果。例如,通过将彩色图像转换为灰度图像。另一方面,我们也可以尝试检测图像中的边缘,以更好地突出字母/单词。
因此,让我们首先通过 Python 脚本在Raspberry Pi上启用文本识别。为此,我们创建一个文件夹和一个文件。
mkdir ocr
cd ocr
sudo nano example.py我们插入以下内容:
import cv2
import pytesseract
import numpy as np
from pytesseract import Output
img_source = cv2.imread('images/coffee.jpg')
def get_grayscale(image):
return cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
def thresholding(image):
return cv2.threshold(image, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)[1]
def opening(image):
kernel = np.ones((5, 5), np.uint8)
return cv2.morphologyEx(image, cv2.MORPH_OPEN, kernel)
def canny(image):
return cv2.Canny(image, 100, 200)
gray = get_grayscale(img_source)
thresh = thresholding(gray)
opening = opening(gray)
canny = canny(gray)
for img in [img_source, gray, thresh, opening, canny]:
d = pytesseract.image_to_data(img, output_type=Output.DICT)
n_boxes = len(d['text'])
# back to RGB
if len(img.shape) == 2:
img = cv2.cvtColor(img, cv2.COLOR_GRAY2RGB)
for i in range(n_boxes):
if int(d['conf'][i]) > 60:
(text, x, y, w, h) = (d['text'][i], d['left'][i], d['top'][i], d['width'][i], d['height'][i])
# don't show empty text
if text and text.strip() != "":
img = cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
img = cv2.putText(img, text, (x, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 1.2, (0, 255, 0), 3)
cv2.imshow('img', img)
cv2.waitKey(0)让我们看看一些有趣的行:
- 导入库(第1-4行)
- 加载图像(第5行),根据需要调整路径!
- 预处理函数,用于转换为灰度值(第9-23行)
- 第32行:在这里,我们提取任何数据(文本、坐标、分数等)
- 为了能够在之后为框着色,如果必要,我们将灰度图像转换回具有颜色通道的图像(第36-37行)
- 从第39行开始,将为分数高于60的框着色。
- 为此,我们在第41行提取文本、起始坐标和框的尺寸。
- 只有当检测到(非空)文本时,我们才绘制框(第43-45行)。
- 然后,我们运行脚本并等待按下转义键(第47/48行)。
我们现在运行脚本:
python3 example.py然后,5张不同的图像会依次出现(按 ESC 键显示下一张图像)。识别出的文本会在图像上被标记出来。这样,您可以确定哪个预处理步骤最适合您。
通过Raspberry Pi摄像头识别实时图像中的文本
到目前为止,我们仅使用静态图像作为文本识别的输入。现在,我们还希望在连接的摄像头的实时流中识别文本。这只需要对我们之前的脚本进行一些小的更改。我们创建一个新文件:
sudo nano ocr_camera.py文件内容如下:
import cv2
import pytesseract
from pytesseract import Output
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1)
while True:
# Capture frame-by-frame
ret, frame = cap.read()
d = pytesseract.image_to_data(frame, output_type=Output.DICT)
n_boxes = len(d['text'])
for i in range(n_boxes):
if int(d['conf'][i]) > 60:
(text, x, y, w, h) = (d['text'][i], d['left'][i], d['top'][i], d['width'][i], d['height'][i])
# don't show empty text
if text and text.strip() != "":
frame = cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
frame = cv2.putText(frame, text, (x, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 0, 255), 3)
# Display the resulting frame
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# When everything done, release the capture
cap.release()
cv2.destroyAllWindows()我们现在的改动如下:
- 在第5-6行,我们定义了相机,而不是固定的图像。相机必须被连接并被识别。
- 在第10行,我们读取了当前的帧。
- 这里我们省略了预处理步骤,但这些步骤也很容易被插入(在第11行)。
最后但同样重要的是,我们也运行了脚本:
python3 ocr_camera.py现在将相机对准文本,观察文本上的单词是如何被识别的:

在我的示例中,你可以清楚地看到转换为灰度图像是有意义的,因为单词“Tutorials”太亮了。
其他语言的文本识别
Tesseract默认只安装了英语作为识别语言。我们可以用以下命令检查:
tesseract --list-langs如果你想添加更多应该识别文本的语言,可以这样做:
sudo apt-get install tesseract-ocr-[lang]将[lang]替换为语言的缩写(all表示安装所有现有的语言)。
https://askubuntu.com/questions/793634/how-do-i-install-a-new-language-pack-for-tesseract-on-16-04/798492#798492
然后你可以在Python脚本中选择语言。添加参数:
d = pytesseract.image_to_data(img, lang='eng')结论
Tesseract是一个强大的工具,它为图像或帧提供了开箱即用的文本识别功能。这意味着我们不需要训练和创建自己的机器学习模型。尽管计算量相对较大,但Raspberry Pi的文本识别效果非常好。通过各种处理步骤,可以进一步改进结果。顺便提一下,你可以在Github仓库中找到这两个脚本。
【原文地址】 https://pimylifeup.com/raspberry-pi-best-operating-systems/